

Stable Diffusionをローカル環境で無料かつ無制限に楽しむ方法
画像生成AIの世界へようこそ!「Stable Diffusion」という名前を聞いたことはありますか? テキストを入力するだけで、まるで魔法のように高品質な画像を生成してくれるこの技術は、今、クリエイターからビジネスパーソンまで、多くの人々を魅了しています。
特に、「自分のPCでStable Diffusionを動かしてみたいけれど、難しそう…」「無料でおすすめの使い方は?」そんな疑問をお持ちの方もいらっしゃるでしょう。この記事では、そんなあなたの疑問をすべて解決します!
Stable Diffusionをローカル環境で無料で使うための簡単導入方法から、最新の活用法、さらには進化し続ける画像生成AIの最新動向まで、どこよりも詳しく、そして分かりやすく解説していきます。この記事を読めば、あなたも今日からStable Diffusionを自由自在に使いこなせるようになりますよ!
📐 図解
Stable Diffusionの基本とローカル環境の魅力
Stable Diffusionとは?進化する画像生成AIの最前線
Stable Diffusionは、イギリスのStability AI社が開発した、オープンソースの画像生成AIモデルです。 2022年8月に公開されて以来、その驚異的な性能と自由度の高さから、世界中で爆発的な人気を博しています。
最大の特徴は、テキスト(プロンプト)を入力するだけで、写真のようにリアルな画像からアニメ調のイラスト、さらには抽象的なアートまで、あらゆる種類の画像を生成できる点です。 その進化は目覚ましく、最新モデルであるStable Diffusion 3.5シリーズは、生成速度や画質の向上はもちろん、手や文字の表現力も格段に向上しています。
▶ あわせて読みたい:「Stable Diffusion」徹底解説!AI画像生成の基礎からプロ活用術まで
Stable Diffusionの魅力は、その無料で利用できる点と、オープンソースであることによる高いカスタマイズ性にあります。 ユーザーは、公開されている様々なモデルやLoRA(追加学習モデル)を組み合わせて、自分だけのオリジナルの画風や表現を作り出すことが可能です。
ローカル環境で使うメリット:自由度とコストパフォーマンス
Stable Diffusionの利用方法は、大きく分けてブラウザ版とローカル版の2つがあります。 ブラウザ版は手軽に始められますが、機能や生成枚数に制限がある場合が多いです。 一方、ローカル環境、つまりご自身のPCにインストールして利用する方法は、初期設定こそ少し手間がかかりますが、そのメリットは計り知れません。
ローカル環境でStable Diffusionを使う最大のメリットは、生成枚数やプロンプトの制限がなく、完全に無料で利用できることです。 自分のPCのスペックさえ許せば、時間や回数を気にすることなく、思う存分画像生成を楽しめます。 また、インターネット接続が不要になるため、プライバシーの面でも安心感があります。 さらに、最新のモデルや拡張機能をいち早く導入し、自分好みにカスタマイズできるのもローカル環境ならではの魅力です。
ただし、ローカル環境での利用には、一定のPCスペックが求められます。 一般的には、NVIDIA製のGPU(VRAM 4GB以上、推奨8GB以上)、Windows 10/11、そして十分なディスク容量(25GB以上、推奨80GB以上)が必要とされています。
▶ あわせて読みたい:【無料】Stable Diffusionをローカルで使う!簡単導入と最新活用法
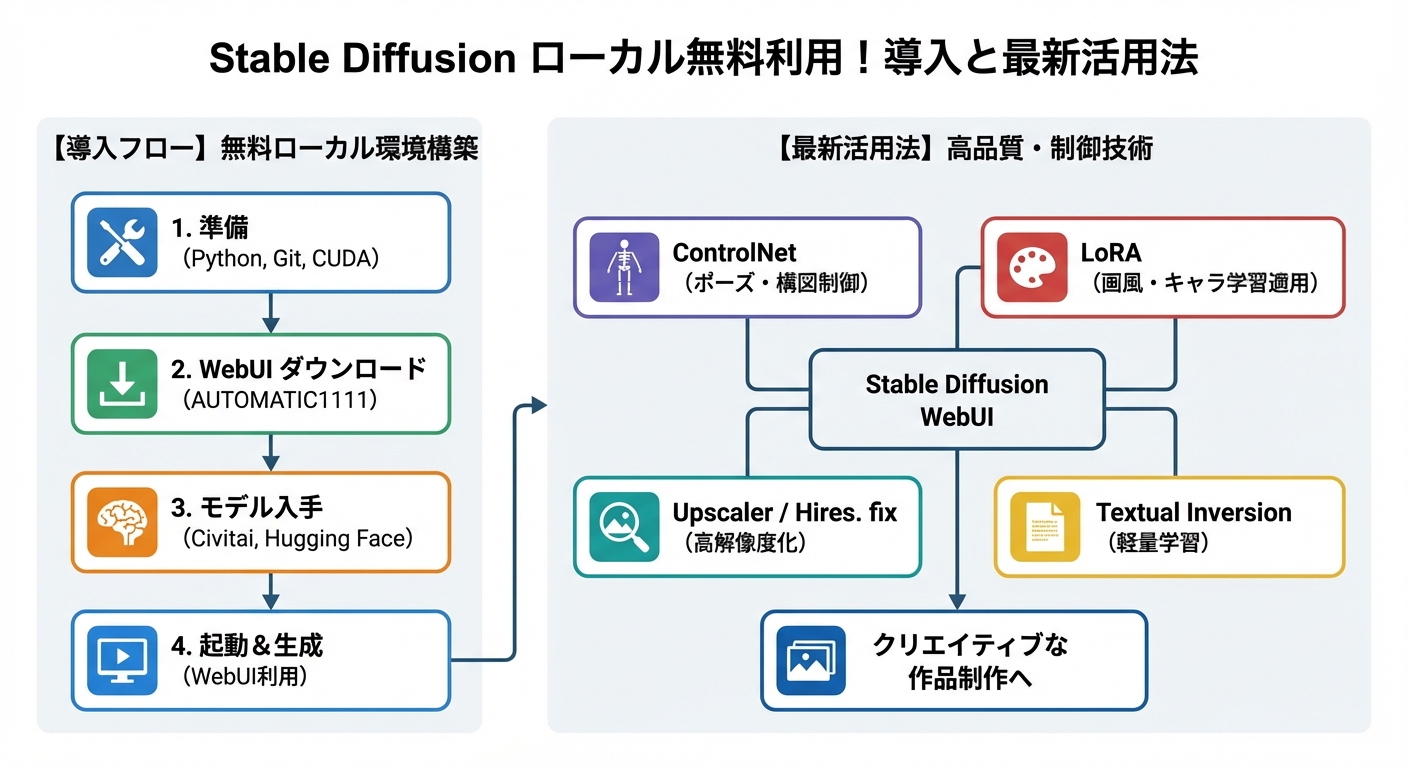
Stable Diffusionをローカル環境に簡単導入!ステップバイステップガイド

導入に必要なもの:PythonとGitの準備
Stable Diffusionをローカル環境で動かすためには、まずいくつかのソフトウェアをPCにインストールする必要があります。 主に、PythonとGitの2つです。
Pythonは、Stable Diffusionのプログラムを実行するために不可欠なプログラミング言語です。 バージョンは3.10.6が推奨されています。 公式サイトからインストーラーをダウンロードし、手順に沿ってインストールしてください。
次に、Gitは、Stable Diffusionの関連ファイルをダウンロード・管理するために必要です。 Gitの公式サイトからインストーラーをダウンロードし、こちらも同様にインストールを進めます。
これらの準備が整ったら、いよいよStable Diffusion本体の導入に移ります。
▶ あわせて読みたい:Swift/CoreMLとStable Diffusionで拓くセマンティック通信の最前線
Stable Diffusion Web UIのインストールと初期設定
Stable Diffusionをより簡単に、そして視覚的に操作できるようにするインターフェースとして、Stable Diffusion Web UI(AUTOMATIC1111版やForge版などがあります)の利用が一般的です。 これをローカルPCにインストールすることで、ブラウザ上で直感的に画像生成を行えるようになります。
インストール手順は、まずGitHubからStable Diffusion Web UIのリポジトリをダウンロードします。 ダウンロードしたフォルダ内にある「webui-user.bat」ファイルを実行することで、Stable Diffusion Web UIが起動します。
初回起動時には、必要なファイルのダウンロードや設定が行われるため、通常より時間がかかります。 気長に待ちましょう。 起動後、ブラウザのアドレスバーに「http://127.0.0.1:7860」と入力することで、Web UIにアクセスできます。
これで、ローカル環境でのStable Diffusionの利用準備は完了です!
モデル・LoRA・VAEなどの導入方法
Stable Diffusionの真価は、その豊富で多様なモデルデータにあります。 モデル(Checkpointとも呼ばれます)は、画像生成のスタイルや画風を決定づける重要な要素です。
Hugging FaceやCivitaiといったサイトで、様々な特徴を持つモデルが公開されています。 気に入ったモデルを見つけたら、ダウンロードして指定のフォルダ(例: `stable-diffusion-webui/models/Stable-diffusion`)に配置します。
同様に、LoRA(Low-Rank Adaptation)は、既存のモデルに追加学習を施し、特定のキャラクター、スタイル、服装などを細かくカスタマイズするための追加学習モデルです。 LoRAもモデルと同様にダウンロードし、所定のフォルダ(例: `stable-diffusion-webui/models/LoRA`)に配置することで利用可能になります。
VAE(Variational Autoencoder)は、生成される画像の品質を向上させるための補足的なモデルです。 これらもモデルと同様にダウンロードし、指定のフォルダに配置することで、画像生成のクオリティをさらに高めることができます。
Stable Diffusionの最新活用法:クリエイティブを加速させるテクニック
プロンプトエンジニアリング:イメージを形にする技術
Stable Diffusionを使いこなす上で最も重要なのが、プロンプトエンジニアリングです。 プロンプトとは、AIに生成してほしい画像の指示文のこと。 どのような言葉を選ぶか、どのように表現するかで、生成される画像のクオリティは劇的に変わります。
基本的なコツとしては、具体的で詳細な指示を与えることが挙げられます。 例えば、「猫」とだけ入力するのではなく、「ふわふわの白い長毛種の猫が、窓辺で日向ぼっこをしている様子、柔らかい光、暖かみのある雰囲気」のように、情景や雰囲気を具体的に描写することで、よりイメージに近い画像を生成できます。
また、ネガティブプロンプト(生成してほしくない要素を指定する指示)も活用することで、意図しないものが画像に含まれるのを防ぎ、クオリティを高めることができます。 例えば、顔が崩れるのを防ぐために「low quality, worst quality, bad anatomy」などをネガティブプロンプトに含めることが一般的です。
強調したい単語には括弧と数字(例: `(beautiful woman:1.2)`)を使用したり、単語の順番を工夫したりすることで、プロンプトの効果をさらに高めることができます。
モデルとLoRAの組み合わせ:無限の表現力
Stable Diffusionの大きな魅力の一つは、モデルとLoRAを自由に組み合わせることで、表現の幅が無限に広がる点です。 基本となるモデルに、特定のキャラクターや画風に特化したLoRAを適用することで、より詳細なカスタマイズが可能になります。
例えば、リアルな人物写真を生成したい場合は、フォトリアリスティックなモデルに、特定の顔立ちや髪型を再現するLoRAを組み合わせる、といった使い方ができます。 アニメ調のイラストを生成したい場合は、アニメ系のモデルに、特定のキャラクターデザインや色彩感覚を持つLoRAを適用することで、より理想に近いイラストを作成できます。
Civitaiなどのコミュニティサイトでは、日々新しいモデルやLoRAが公開されており、それらを試すことで、常に最新のトレンドを取り入れた画像生成を楽しむことができます。
img2imgとInpaint:既存画像を基にした高度な編集
Stable Diffusionには、テキストから画像を生成する「txt2img」機能だけでなく、既存の画像を基に新しい画像を生成する「img2img」や、画像の一部を修正・加筆する「Inpaint」といった高度な機能も搭載されています。
img2img機能を使えば、ラフスケッチや既存の画像を元に、より高品質で詳細な画像を生成したり、画風を変換したりすることが可能です。 例えば、簡単な線画からリアルな風景画を生成したり、写真の雰囲気をアニメ調に変えたりといった応用ができます。
Inpaint機能は、生成された画像の一部に修正を加えたい場合に非常に便利です。 例えば、人物の表情を変えたい、不要なオブジェクトを削除したい、といった場合に、修正したい箇所を指定してプロンプトを入力することで、自然な形で画像を編集できます。

ひできち: 😊 Stable Diffusionのローカル環境導入、これであなたも自由自在に画像生成を楽しめますね!最初の一歩を踏み出すのは少し勇気がいるかもしれませんが、ぜひ色々なプロンプトで試してみてください。自分だけの表現が見つかるはずですよ!
🎬 関連動画
Stable Diffusionの最新動向とビジネス応用
進化を続けるStable Diffusion:最新モデルと技術動向
Stable Diffusionは、その開発スピードが非常に速いことでも知られています。 常に新しいモデルや機能が発表され、画像生成AIの技術は日々進化しています。
特に注目すべきは、Stable Diffusion 3.5シリーズの登場です。 この最新モデルは、従来のバージョンと比較して、高解像度・高精度な画像生成能力が大幅に向上し、特に手や文字の表現力が飛躍的に改善されました。 さらに、Diffusion TransformerやRectified Flowといった最新技術の導入により、文章の理解度やプロンプトへの忠実度も向上しています。
また、生成速度を向上させるための軽量版モデルや、特定の用途に特化したモデルも続々と登場しており、ユーザーは自分の目的に合わせて最適なモデルを選択できるようになっています。
ビジネスシーンでの活用事例:効率化と新たな価値創造
Stable Diffusionは、その高い性能と自由度から、様々なビジネスシーンでの活用が期待されています。 例えば、マーケティング素材の制作において、広告バナーやSNS投稿用の画像を短時間で大量に生成することが可能です。 これにより、デザイン制作にかかるコストと時間を大幅に削減できます。
また、プレゼン資料やWebサイトのデザイン案作成においても、アイデア出しの段階で多様なビジュアルを迅速に生成し、より効果的なデザインを検討することができます。
さらに、ゲーム開発や映像制作の分野では、キャラクターデザイン、背景、アイテムなどのアセット生成に活用することで、制作プロセスを効率化し、クリエイティブな表現の幅を広げることができます。
Stable Diffusionで生成した画像は、多くの場合商用利用が可能ですが、利用するモデルのライセンスを事前に確認することが重要です。
ひできち: 😊 最新の活用法や事例を参考に、あなたのクリエイティブなアイデアをどんどん形にしていきましょう!Stable Diffusionは、想像力を無限に広げてくれる強力なツールです。遊び感覚でどんどん試して、新しい発見を楽しんでくださいね。
Stable Diffusion 活用事例
💼 活用事例
ある中小企業のマーケティング担当者は、SNSキャンペーン用の魅力的な画像を迅速に作成するためにStable Diffusionを導入しました。 以前は、デザイナーに依頼するか、ストックフォトを利用していましたが、コストと時間がかかっていました。 Stable Diffusionをローカル環境に導入し、ターゲット層の興味を引くような具体的なプロンプトを作成・試行錯誤することで、キャンペーンのテーマに沿った高品質な画像を短時間で大量に生成できるようになりました。 これにより、キャンペーンのリーチとエンゲージメントが大幅に向上し、結果として売上増加にも繋がりました。 特に、複数のデザイン案を素早く比較検討できたことが、成功の鍵となりました。
ひできち: 😊 Stable Diffusionの進化は本当に目覚ましいですよね。最新動向を追いかけながら、ぜひ色々なWeb UIも試して、あなたにぴったりの環境を見つけてみてください。きっと、もっと楽しく、効率的に創作活動ができるようになりますよ!
比較表:Stable Diffusion Web UIの種類
| 項目 | AUTOMATIC1111版 | Forge | ComfyUI |
|---|---|---|---|
| 特徴 | 最も一般的で機能が豊富。拡張機能も多数。 | パフォーマンスとメモリ効率に優れ、高速生成が可能。 | ノードベースのUIで、複雑なワークフロー構築に最適。 |
| 操作性 | 比較的直感的で初心者にも扱いやすい。 | AUTOMATIC1111に近い操作感で、初心者でも導入しやすい。 | 学習コストは高いが、自由度と柔軟性が非常に高い。 |
| 得意なこと | 汎用的な画像生成、多様な拡張機能の利用。 | 大量生成、連続処理、高速な画像生成。 | 複雑な画像生成ワークフローの構築、実験的な試み。 |
| 初心者向け | 〇 | 〇 | △(学習が必要) |
| 参考リンク | GitHub | GitHub | GitHub |
よくある質問
Q: Stable Diffusionをローカルで使うために必要なPCスペックは?
A: 最低でもNVIDIA製のGPU(VRAM 4GB以上)、Windows 10/11、ディスク空き容量25GB以上が必要です。より快適に利用するには、VRAM 8GB以上、SSD搭載のPCを推奨します。
Q: Stable DiffusionのモデルやLoRAはどこで入手できますか?
A: Hugging FaceやCivitaiといったサイトで、数多くのモデルやLoRAが公開されています。これらのサイトからダウンロードして利用できます。
Q: Stable Diffusionで生成した画像は商用利用できますか?
A: 多くの場合、商用利用は可能ですが、使用するモデルのライセンスを必ず確認する必要があります。モデルによっては商用利用に制限がある場合があります。
Q: プロンプトの書き方が難しいのですが、コツはありますか?
A: 具体的な情景や雰囲気を詳細に描写することが重要です。また、ネガティブプロンプトを活用したり、強調したい単語を括弧で囲んだりするテクニックも有効です。
Q: ローカル環境でのインストールがうまくいきません。どうすれば良いですか?
A: PythonやGitのバージョンが正しいか、インストール手順を再度確認してみてください。また、公式ドキュメントやコミュニティフォーラムで情報を探すことも有効です。
まとめ
Stable Diffusionをローカル環境で無料で利用することは、画像生成AIの可能性を最大限に引き出すための強力な一歩です。初期設定にはPCスペックの準備やソフトウェアのインストールが必要ですが、一度環境を構築してしまえば、生成枚数や機能の制限なく、あなたの創造性を自由に解き放つことができます。
最新モデルの導入や、モデル・LoRAの組み合わせによる無限の表現力の探求、そしてプロンプトエンジニアリングの技術を磨くことで、より高品質で意図通りの画像を生成できるようになります。今回ご紹介した導入方法や活用テクニックを参考に、ぜひStable Diffusionの世界を体験してみてください。あなたのクリエイティブな活動が、さらに加速すること間違いなしです!
ひできち
AIにハマっています。毎日AIと対話しながら、画像生成・プロンプト設計・Webツール開発に取り組んでいます。ChatGPT、Gemini、Claude、Cursor——あらゆるAIツールを実際に使い倒し、本当に役立つ情報だけをお届けします。理論より実践。使ってみて分かったリアルな活用法を発信中。
プロフィールを見る →

コメント